-Others while we debug.
That is very weird. Could you modify the DCTCP script to spawn the CLI just before the experiment starts, so you can check whether the "red" qdisc is actually getting installed?
thanks,
--
Vimal
************************************************************************************************
The red queue on the switch, right? The one on h1 looked similar. Both
showed 0 for dropped, overlimits, and marked. Shouldn't it be non-zero
afterwards?
before
qdisc red 6: dev s1-eth1 parent 5:1 limit 1000000b min 30000b max 35000b ecn
Sent 1446 bytes 19 pkt (dropped 0, overlimits 0 requeues 0)
backlog 0b 0p requeues 0
marked 0 early 0 pdrop 0 other 0
after
qdisc red 6: dev s1-eth1 parent 5:1 limit 1000000b min 30000b max 35000b ecn
Sent 1594 bytes 21 pkt (dropped 0, overlimits 0 requeues 0)
backlog 0b 0p requeues 0
marked 0 early 0 pdrop 0 other 0
Full output:
shewa@h0:~/src/mininet_tests/dctcp$ ./run-dctcp.sh
net.ipv4.tcp_dctcp_enable = 0
net.ipv4.tcp_ecn = 0
net.ipv4.tcp_dctcp_enable = 1
net.ipv4.tcp_ecn = 1
~~~~~~~~~~~~~~~~~> BW = 100.0
*** Creating network
*** Adding controller
*** Adding hosts:
h1 h2 h3
*** Adding switches:
s1
*** Adding links:
(100.00Mbit ECN) (100.00Mbit ECN) (h1, s1) (100.00Mbit 0.075ms 0.05ms
distribution normal delay) (100.00Mbit 0.075ms 0.05ms distribution
normal delay) (h2, s1) (100.00Mbit 0.075ms 0.05ms distribution
normal delay) (100.00Mbit 0.075ms 0.05ms distribution normal
delay) (h3, s1)
*** Configuring hosts
h1 (cfs -1/100000us) h2 (cfs -1/100000us) h3 (cfs -1/100000us)
*** Starting controller
*** Starting 1 switches
s1 (100.00Mbit ECN) (100.00Mbit 0.075ms 0.05ms distribution normal
delay) (100.00Mbit 0.075ms 0.05ms distribution normal delay)
PING 10.0.0.2 (10.0.0.2) 56(84) bytes of data.
64 bytes from 10.0.0.2: icmp_req=1 ttl=64 time=2.40 ms
64 bytes from 10.0.0.2: icmp_req=2 ttl=64 time=1.07 ms
--- 10.0.0.2 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 1001ms
rtt min/avg/max/mdev = 1.075/1.741/2.408/0.667 ms
*** Starting CLI:
mininet> s1 tc -s qdisc
qdisc mq 0: dev eth0 root
Sent 830689151 bytes 682384 pkt (dropped 0, overlimits 0 requeues 0)
backlog 0b 0p requeues 0
qdisc mq 0: dev eth1 root
Sent 670 bytes 5 pkt (dropped 0, overlimits 0 requeues 0)
backlog 0b 0p requeues 0
qdisc htb 5: dev s1-eth1 root refcnt 2 r2q 10 default 1 direct_packets_stat 0
Sent 1446 bytes 19 pkt (dropped 0, overlimits 0 requeues 0)
backlog 0b 0p requeues 0
qdisc red 6: dev s1-eth1 parent 5:1 limit 1000000b min 30000b max 35000b ecn
Sent 1446 bytes 19 pkt (dropped 0, overlimits 0 requeues 0)
backlog 0b 0p requeues 0
marked 0 early 0 pdrop 0 other 0
qdisc netem 10: dev s1-eth1 parent 6: limit 425
Sent 1446 bytes 19 pkt (dropped 0, overlimits 0 requeues 0)
backlog 0b 0p requeues 0
qdisc htb 5: dev s1-eth2 root refcnt 2 r2q 10 default 1 direct_packets_stat 0
Sent 1458 bytes 19 pkt (dropped 0, overlimits 17 requeues 0)
backlog 0b 0p requeues 0
qdisc netem 10: dev s1-eth2 parent 5:1 limit 1000000 delay 74us 49us
Sent 1458 bytes 19 pkt (dropped 0, overlimits 0 requeues 0)
backlog 0b 0p requeues 0
qdisc htb 5: dev s1-eth3 root refcnt 2 r2q 10 default 1 direct_packets_stat 0
Sent 1154 bytes 15 pkt (dropped 0, overlimits 14 requeues 0)
backlog 0b 0p requeues 0
qdisc netem 10: dev s1-eth3 parent 5:1 limit 1000000 delay 74us 49us
Sent 1154 bytes 15 pkt (dropped 0, overlimits 0 requeues 0)
backlog 0b 0p requeues 0
mininet> quit
1 seconds left
*** Starting CLI:
mininet> s1 tc -s qdisc
qdisc mq 0: dev eth0 root
Sent 850160497 bytes 700768 pkt (dropped 0, overlimits 0 requeues 0)
backlog 0b 0p requeues 0
qdisc mq 0: dev eth1 root
Sent 670 bytes 5 pkt (dropped 0, overlimits 0 requeues 0)
backlog 0b 0p requeues 0
qdisc htb 5: dev s1-eth1 root refcnt 2 r2q 10 default 1 direct_packets_stat 0
Sent 1594 bytes 21 pkt (dropped 0, overlimits 0 requeues 0)
backlog 0b 0p requeues 0
qdisc red 6: dev s1-eth1 parent 5:1 limit 1000000b min 30000b max 35000b ecn
Sent 1594 bytes 21 pkt (dropped 0, overlimits 0 requeues 0)
backlog 0b 0p requeues 0
marked 0 early 0 pdrop 0 other 0
qdisc netem 10: dev s1-eth1 parent 6: limit 425
Sent 1594 bytes 21 pkt (dropped 0, overlimits 0 requeues 0)
backlog 0b 0p requeues 0
qdisc htb 5: dev s1-eth2 root refcnt 2 r2q 10 default 1 direct_packets_stat 0
Sent 1512 bytes 20 pkt (dropped 0, overlimits 18 requeues 0)
backlog 0b 0p requeues 0
qdisc netem 10: dev s1-eth2 parent 5:1 limit 1000000 delay 74us 49us
Sent 1512 bytes 20 pkt (dropped 0, overlimits 0 requeues 0)
backlog 0b 0p requeues 0
qdisc htb 5: dev s1-eth3 root refcnt 2 r2q 10 default 1 direct_packets_stat 0
Sent 1282 bytes 17 pkt (dropped 0, overlimits 16 requeues 0)
backlog 0b 0p requeues 0
qdisc netem 10: dev s1-eth3 parent 5:1 limit 1000000 delay 74us 49us
Sent 1282 bytes 17 pkt (dropped 0, overlimits 0 requeues 0)
backlog 0b 0p requeues 0
************************************************************************************************
Forget dropped/overlimits -- from your output before/after the experiment it seems like most of the bytes were sent out of eth0. Are you sure TCP is even senidng data on the right interfaces? Can you check the throughput during the experiment?
ethstats is a nice tool (sudo apt-get install ethstats; ethstats -n1)
--
Vimal
************************************************************************************************
Yes.
The bwm-ng monitoring graph shows 100Mbps over s1-eth1. I turned
bwm-ng off and monitored with ethstats (apparently they can't both run
simultaneously) and it agrees.
$ ethstats -n1 &> /tmp/ethstats.txt
$ cat /tmp/ethstats.txt | grep s1-eth1 | sort | uniq -c
1 s1-eth1: 0.00 Mb/s In 0.00 Mb/s Out - 4293979006.0
p/s In 4293977900.0 p/s Out
1 s1-eth1: 0.00 Mb/s In 0.00 Mb/s Out - 4293987295.0
p/s In 4293986192.0 p/s Out
1 s1-eth1: 0.00 Mb/s In 0.00 Mb/s Out - 4294959007.0
p/s In 4294959004.0 p/s Out
1 s1-eth1: 0.00 Mb/s In 0.00 Mb/s Out - 980001.0 p/s In
981104.0 p/s Out
1 s1-eth1: 4.86 Mb/s In 100.29 Mb/s Out - 8241.0 p/s In
8287.0 p/s Out
1 s1-eth1: 4.86 Mb/s In 100.30 Mb/s Out - 8261.0 p/s In
8297.0 p/s Out
...
Since bwm-ng and ethstats conflicted, I assume that so does 'tc -s
qdisc' ... so I reran with just it.
Now it shows the traffic going through s1-eth1 and the red queue. But
it still doesn't show any
marked packets. HTB shows overlimits for each switch interface, but I
don't see anything else.
before:
qdisc mq 0: dev eth0 root
Sent 365727120 bytes 290930 pkt (dropped 0, overlimits 0 requeues 1)
backlog 0b 0p requeues 1
qdisc mq 0: dev eth1 root
Sent 1012 bytes 6 pkt (dropped 0, overlimits 0 requeues 0)
backlog 0b 0p requeues 0
qdisc htb 5: dev s1-eth1 root refcnt 2 r2q 10 default 1 direct_packets_stat 0
Sent 702 bytes 9 pkt (dropped 0, overlimits 0 requeues 0)
backlog 0b 0p requeues 0
qdisc red 6: dev s1-eth1 parent 5:1 limit 1000000b min 30000b max 35000b ecn
Sent 702 bytes 9 pkt (dropped 0, overlimits 0 requeues 0)
backlog 0b 0p requeues 0
marked 0 early 0 pdrop 0 other 0
qdisc netem 10: dev s1-eth1 parent 6: limit 425
Sent 702 bytes 9 pkt (dropped 0, overlimits 0 requeues 0)
backlog 0b 0p requeues 0
qdisc htb 5: dev s1-eth2 root refcnt 2 r2q 10 default 1 direct_packets_stat 0
Sent 620 bytes 8 pkt (dropped 0, overlimits 7 requeues 0)
backlog 0b 0p requeues 0
qdisc netem 10: dev s1-eth2 parent 5:1 limit 1000000 delay 74us 49us
Sent 620 bytes 8 pkt (dropped 0, overlimits 0 requeues 0)
backlog 0b 0p requeues 0
qdisc htb 5: dev s1-eth3 root refcnt 2 r2q 10 default 1 direct_packets_stat 0
Sent 316 bytes 4 pkt (dropped 0, overlimits 4 requeues 0)
backlog 0b 0p requeues 0
qdisc netem 10: dev s1-eth3 parent 5:1 limit 1000000 delay 74us 49us
Sent 316 bytes 4 pkt (dropped 0, overlimits 0 requeues 0)
backlog 0b 0p requeues 0
after:
qdisc mq 0: dev eth0 root
Sent 483556337 bytes 377972 pkt (dropped 0, overlimits 0 requeues 1)
backlog 0b 0p requeues 1
qdisc mq 0: dev eth1 root
Sent 1012 bytes 6 pkt (dropped 0, overlimits 0 requeues 0)
backlog 0b 0p requeues 0
qdisc htb 5: dev s1-eth1 root refcnt 2 r2q 10 default 1 direct_packets_stat 0
Sent 1502786766 bytes 993579 pkt (dropped 0, overlimits 1953808 requeues 0)
backlog 0b 0p requeues 0
qdisc red 6: dev s1-eth1 parent 5:1 limit 1000000b min 30000b max 35000b ecn
Sent 1502786766 bytes 993579 pkt (dropped 0, overlimits 0 requeues 0)
backlog 0b 0p requeues 0
marked 0 early 0 pdrop 0 other 0
qdisc netem 10: dev s1-eth1 parent 6: limit 425
Sent 1502786766 bytes 993579 pkt (dropped 0, overlimits 0 requeues 0)
backlog 0b 0p requeues 0
qdisc htb 5: dev s1-eth2 root refcnt 2 r2q 10 default 1 direct_packets_stat 0
Sent 36634038 bytes 492727 pkt (dropped 0, overlimits 562072 requeues 0)
backlog 0b 0p requeues 0
qdisc netem 10: dev s1-eth2 parent 5:1 limit 1000000 delay 74us 49us
Sent 36634038 bytes 492727 pkt (dropped 0, overlimits 0 requeues 0)
backlog 0b 0p requeues 0
qdisc htb 5: dev s1-eth3 root refcnt 2 r2q 10 default 1 direct_packets_stat 0
Sent 37156074 bytes 499835 pkt (dropped 0, overlimits 568936 requeues 0)
backlog 0b 0p requeues 0
qdisc netem 10: dev s1-eth3 parent 5:1 limit 1000000 delay 74us 49us
Sent 37156074 bytes 499835 pkt (dropped 0, overlimits 0 requeues 0)
backlog 0b 0p requeues 0
-- Andrew Shewmaker
************************************************************************************************
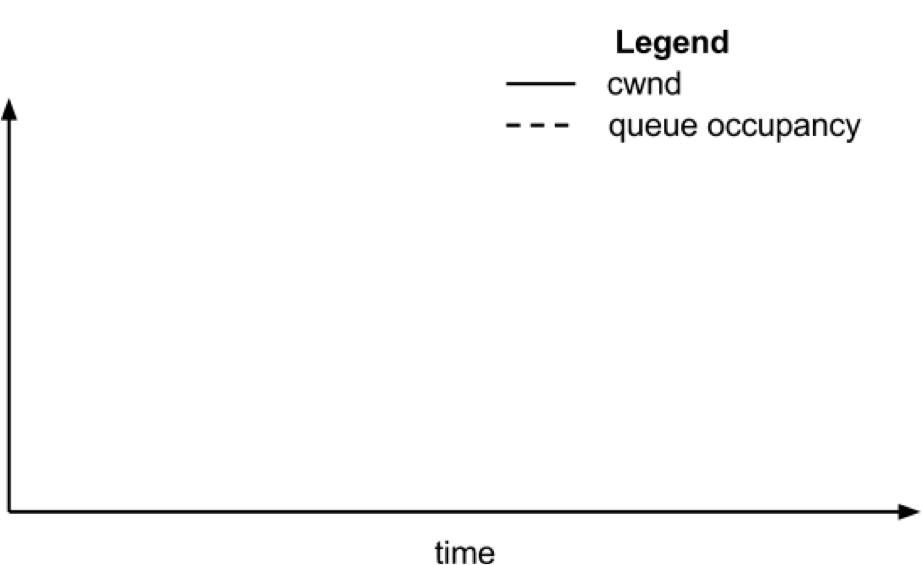
Thanks! Looking at the queue sizes and the cwnd plots, it seems like DCTCP is working. The graph with TCP would look very different with pronounced sawtooths.
Can you confirm that the RED queue does ECN marking by doing a tcpdump at s1-eth1 and checking for ECN marked packets (tcpdump -ni s1-eth1 'ip && (ip[1]&0x3==0x3)'? I am guessing the bug is that RED isn't reporting stats correctly....
bwm-ng and ethstats read /proc/net/dev to report stats. tc doesn't use that interface, so you can run it with the other tools. Though I wonder why bwm-ng and ethstats lock /proc/net/dev....
--
Vimal
************************************************************************************************
I ran the tcpdump outside of mininet and didn't see anything.
I added the above tcpdump to dctcp.py to run alongside the others
already built into the script for the hosts, and I'm getting an empty
pcap file for the switch and none for the hosts. I checked stderr in
their Popen objects and they're all getting:
setns: Bad address
I didn't see that error (or anything useful) when I executed by hand in mininet:
mininet> s1 tcpdump -ni s1-eth1 'ip && (ip[1]&0x3==0x3)'
I'm still looking into that error message.
-- Andrew Shewmaker
************************************************************************************************
Hmm, could you see what tcpdump -ni s1-eth1 'ip && (ip[1]&0x3==0x2)' outputs? This checks for ECN capable packets that are not ECN marked. You needn't have to run it inside Mininet -- it should work in the root namespace as well.
--
Vimal
************************************************************************************************
It looks like everything is ECN capable, but no ECN markings.
shewa@h0:~/src/mininet_tests/dctcp$ uname -r; sudo tcpdump -ni s1-eth1
-s0 -w /tmp/s1-eth1.pcap
3.2.18dctcp3
tcpdump: WARNING: s1-eth1: no IPv4 address assigned
tcpdump: listening on s1-eth1, link-type EN10MB (Ethernet), capture
size 65535 bytes
tcpdump: pcap_loop: The interface went down
1733228 packets captured
1969960 packets received by filter
236683 packets dropped by kernel
shewa@h0:~/src/mininet_tests/dctcp$ sudo tcpdump -n -r
/tmp/s1-eth1.pcap 'ip && (ip[1]&0x3==0x3)'
reading from file /tmp/s1-eth1.pcap, link-type EN10MB (Ethernet)
shewa@h0:~/src/mininet_tests/dctcp$ sudo tcpdump -n -r
/tmp/s1-eth1.pcap 'ip && (ip[1]&0x3==0x2)'
...
many, many lines
...
10:27:03.377120 IP 10.0.0.2.60928 > 10.0.0.1.5001: Flags [.], seq
594378104:594379552, ack 1, win 29, options [nop,nop,TS val 804230 ecr
804229], length 1448
10:27:03.377148 IP 10.0.0.1.5001 > 10.0.0.2.60928: Flags [.], ack
594382448, win 1076, options [nop,nop,TS val 804268 ecr 804230],
length 0
10:27:03.377241 IP 10.0.0.2.60928 > 10.0.0.1.5001: Flags [.], seq
594382448:594383896, ack 1, win 29, options [nop,nop,TS val 804230 ecr
804229], length 1448
10:27:03.377285 IP 10.0.0.1.5001 > 10.0.0.2.60928: Flags [.], ack
594383896, win 1076, options [nop,nop,TS val 804268 ecr 804230],
length 0
10:27:03.377362 IP 10.0.0.2.60928 > 10.0.0.1.5001: Flags [P.], seq
594383896:594384008, ack 1, win 29, options [nop,nop,TS val 804230 ecr
804229], length 112
10:27:03.377371 IP 10.0.0.2.60928 > 10.0.0.1.5001: Flags [F.], seq
594384008, ack 1, win 29, options [nop,nop,TS val 804232 ecr 804231],
length 0
10:27:03.383468 IP 10.0.0.1.5001 > 10.0.0.2.60928: Flags [F.], seq 1,
ack 594384009, win 1076, options [nop,nop,TS val 804275 ecr 804232],
length 0
10:27:03.383506 IP 10.0.0.1.5001 > 10.0.0.3.43140: Flags [F.], seq 0,
ack 838574850, win 1726, options [nop,nop,TS val 804275 ecr 804225],
length 0
10:27:03.383633 IP 10.0.0.2.60928 > 10.0.0.1.5001: Flags [.], ack 2,
win 29, options [nop,nop,TS val 804275 ecr 804275], length 0
10:27:03.383680 IP 10.0.0.3.43140 > 10.0.0.1.5001: Flags [.], ack 1,
win 29, options [nop,nop,TS val 804275 ecr 804275], length 0
************************************************************************************************
Hmm, that is very weird.
OK, let's try something else. Here is a modified htb module that does ECN marking:
http://stanford.edu/~jvimal/htb-ecn/
You might have to:
* edit the experiment script to remove RED qdisc from being added
* rmmod sch_htb before running any experiment
* download the two files from the link above and type "make" to create a new sch_htb.ko module
* insmod /path/to/new/sch_htb.ko ecn_thresh_packets=30
* make sure the expt script doesn't do "rmmod sch_htb"... if so, comment it out
* rerun the experiments, checking for ECN marks both on both s1-eth1 as well as the host that receives the two flows (mininet> hN tcpdump ... hN-eth0 'ip &&...' )
And see what happens. Since the queue occupancy output suggests that it is greater than 300, packets must be marked....
--
Vimal
************************************************************************************************
That worked. Thanks!
My tcpdump on s1-eth1 sees ECN marked packets and the bottleneck queue
length is mostly between 23 and 32 packets. 50MB/s per flow.
I wonder why red isn't working on any of the systems I tested, but I
suppose the main thing is that your htb module does.
Again, thank you so much.
Andrew
************************************************************************************************
+Others.
Glad it worked.
@all: It appears the DCTCP bug was due the RED module
not ECN marking packets. A custom htb module that did
ECN marking seems to have resolved the issue.
Andrew: Here is a pointer if you want to further debug
this:
1. Look at the red_enqueue function: http://lxr.free-electrons.com/source/net/sched/sch_red.c?v=3.2#L57
2. Line 74 does the ECN marking but it's conditioned on a few cases. It's worth checking if those conditions are triggered.
And, here is a patch to modify sch_htb.c from any recent
kernel. It's worth keeping it safe somewhere since my
webpage might not be around forever.
@@ -39,6 +39,7 @@
#include <linux/slab.h>
#include <net/netlink.h>
#include <net/pkt_sched.h>
+#include <net/inet_ecn.h>
/* HTB algorithm.
Author: devik@cdi.cz
@@ -64,6 +65,10 @@
module_param (htb_hysteresis, int, 0640);
MODULE_PARM_DESC(htb_hysteresis, "Hysteresis mode, less CPU load, less accurate");
+static int ecn_thresh_packets __read_mostly = 0; /* 0 disables it */
+module_param(ecn_thresh_packets, int, 0640);
+MODULE_PARM_DESC(ecn_thresh_packets, "ECN marking threshold in packets");
+
/* used internaly to keep status of single class */
enum htb_cmode {
HTB_CANT_SEND, /* class can't send and can't borrow */
@@ -552,6 +557,9 @@
struct htb_sched *q = qdisc_priv(sch);
struct htb_class *cl = htb_classify(skb, sch, &ret);
+ if (ecn_thresh_packets && (sch->q.qlen >= ecn_thresh_packets))
+ INET_ECN_set_ce(skb);
+
if (cl == HTB_DIRECT) {
/* enqueue to helper queue */
if (q->direct_queue.qlen < q->direct_qlen) {
--
Vimal
************************************************************************************************
Thanks, Vimal! I'll let you know if I fix a bug.
-- Andrew Shewmaker
************************************************************************************************
************************************************************************************************